We Test The AI Models UK Customers Actually Use
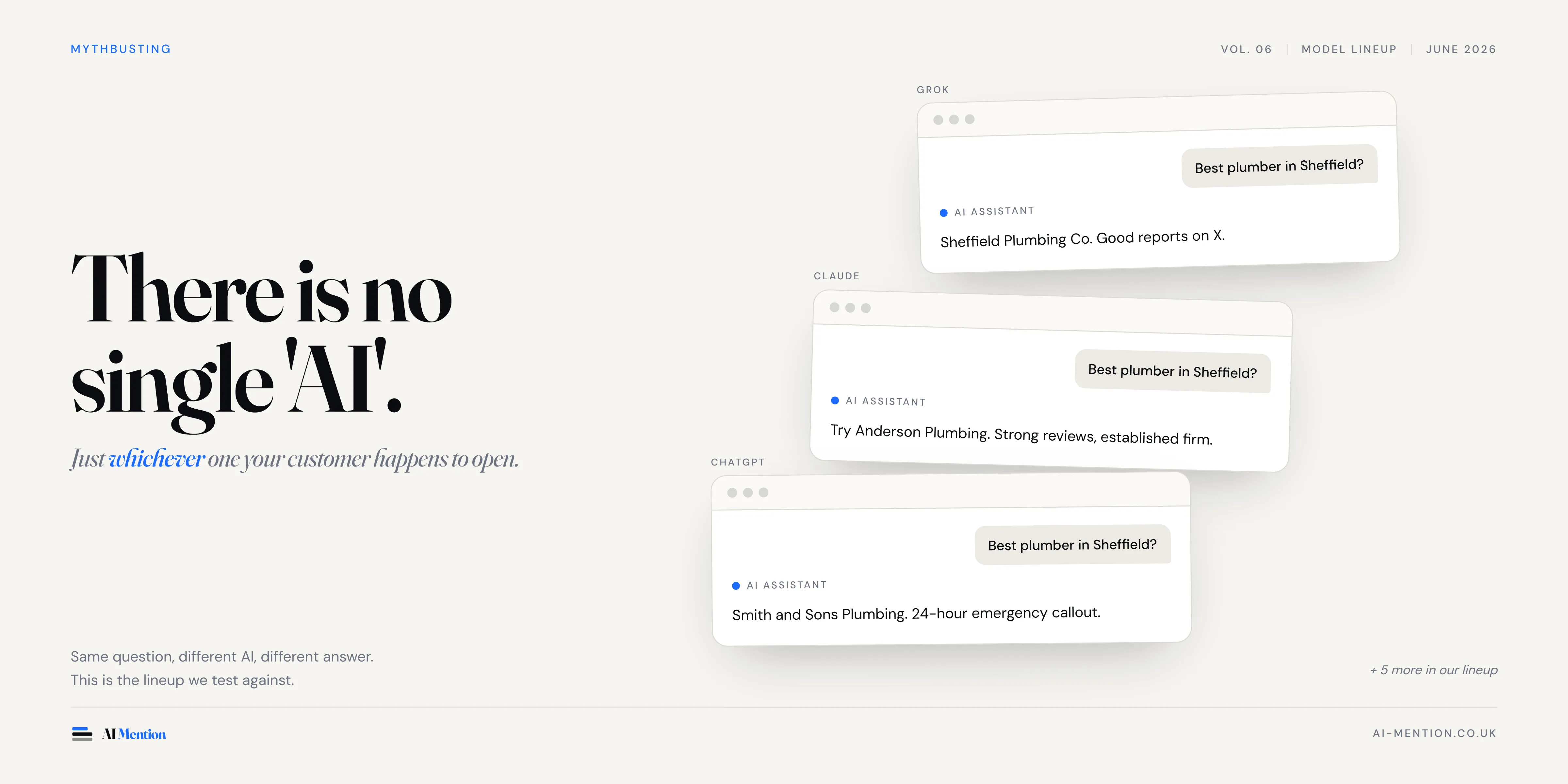
When someone asks an AI for a local plumber in Sheffield, they are not asking "AI". They are asking a specific tool - the one open in their browser tab, or the one their phone defaulted to, or the one their friend told them to try last week.
That distinction matters more than it sounds. ChatGPT and Gemini do not give the same answer. Free-tier Claude and paid-tier Claude do not give the same answer. And then there are the models most people have never heard of, quietly serving recommendations inside the tools your customers actually use.
If you want to know how AI is recommending your business, the only honest test is one that runs across the AI your customers are using. Not the big four. The actual lineup.
This post explains how we choose what to test, what is in our lineup today, and why a "small" model still matters when it recommends one of your competitors.
The four everyone names
Most "AI visibility" coverage stops at four brands: ChatGPT, Claude, Gemini, Perplexity. They are the obvious ones. They cover the bulk of consumer AI use. And they are not enough.
The first hole in the four-brand framing is variant blindness. "ChatGPT" is not one product. The consumer-tier model a free user encounters and the paid-tier model a developer pays for are different models, trained differently, returning different recommendations. The same is true for Claude, for Gemini, for Perplexity. A test against "ChatGPT" without naming which variant tells you almost nothing about which ChatGPT your customers are actually using.
The second hole is that the four-brand list itself is incomplete in the UK in 2026. New entries with real UK consumer traction sit outside it. Models surfaced through routing inside paid tiers of the four big names sit outside it. A check that names four brands and stops there is testing against a partial picture of how UK customers actually find businesses.
What UK consumers are actually using right now
The honest answer to "which models should an AI visibility test cover" is "the ones UK consumers are actually using to ask for recommendations". That is the principle the lineup is built on, and the snapshot today comes to eight platforms across twelve model variants.
The four every customer recognises: ChatGPT, Claude, Gemini, Perplexity. We test multiple versions of each, because the model a free user encounters and the model a paying user encounters do not give the same answers.
Then there are the platforms that sit outside the obvious four. Grok, built into X. DeepSeek, an open-weights model gaining traction in technical communities. Both have growing UK presence, especially for current-events queries on Grok and developer-adjacent search on DeepSeek.
And then there are the models most people have never heard of. Moonshot AI's Kimi. NVIDIA's Nemotron. Most people will never deliberately choose them, but they are routinely returned when someone pays for Perplexity Pro and asks for a recommendation. If your customer is using Perplexity Pro and the answer comes back from Kimi, you want a check that looked at Kimi.
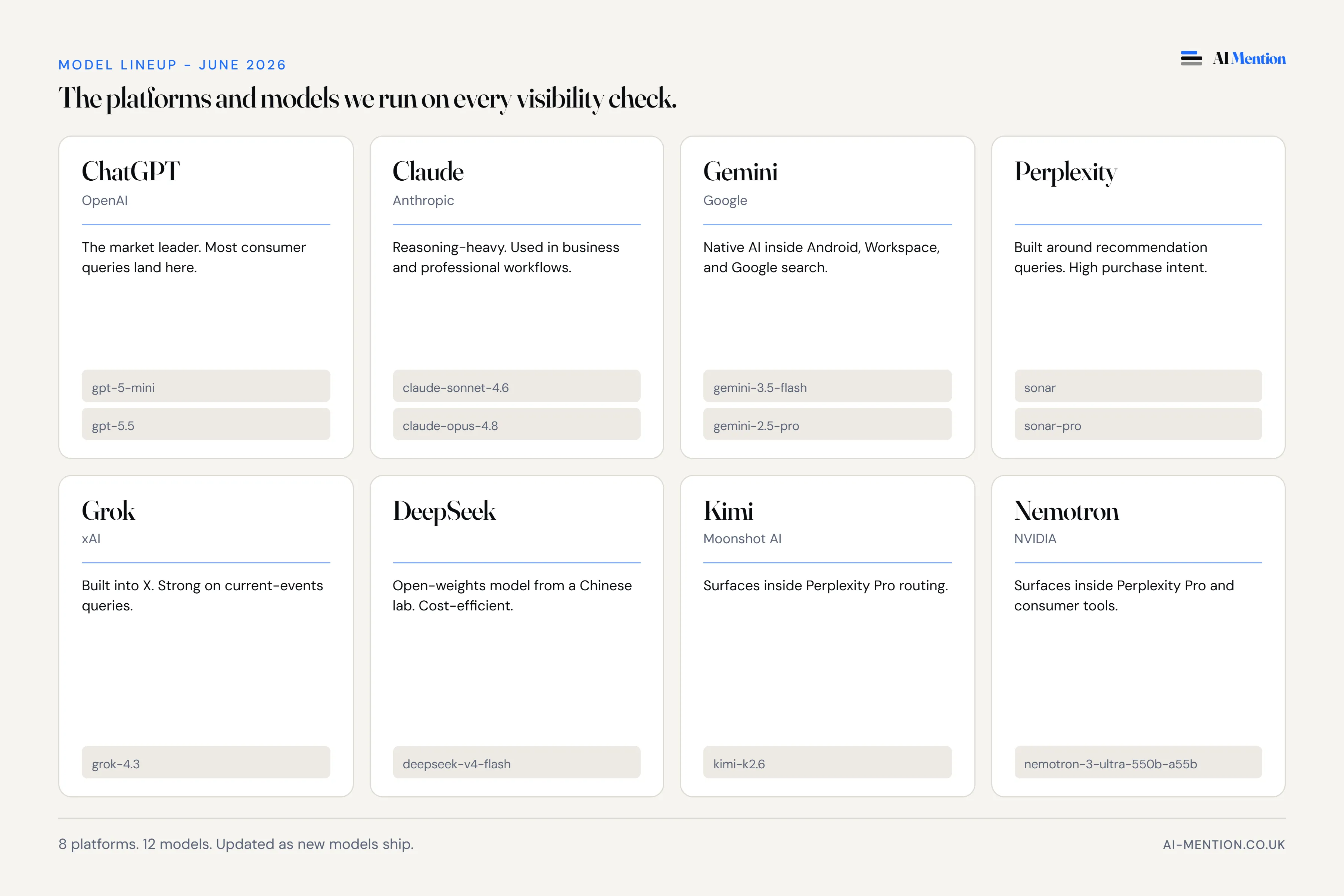
The full live lineup is on our /models page. The point of writing it out here is not "look how many we have". The point is that "AI visibility" in the UK today is not four brand names, and pretending it is leaves blind spots in any audit you might pay for.
Big usage and small usage both matter
There is a temptation to say "ChatGPT has hundreds of millions of users, just test that". It is wrong, and it is wrong in a specific way.
ChatGPT pulling huge volume does not mean the other platforms are noise. A small platform that recommends one local plumber in Sheffield has still recommended a local plumber in Sheffield. If that plumber is your competitor and the customer rang them instead of you, your business is no less hurt because the recommending platform had a smaller user base. Outcomes do not scale to platform size.
This is why we test the small-but-real platforms alongside the giants. Kimi inside Perplexity Pro routing might serve a tiny fraction of UK recommendation queries this year. If even one of those queries is from a customer in your area and the answer it gives is not you, you wanted to know. A check that does not look at Kimi tells you nothing about that customer.
The lineup is not static
We do not pick a model lineup once and forget about it. The lineup is what the market is using now. As the market shifts, so does the lineup.
When new models gain real UK consumer traction, they join. When older models fade and stop being used, they leave. The list moves as the market does.
That movement is the point, not a footnote. The snapshot today is eight platforms, twelve models. Six months from now the list may look different. That is by design.
What this means for your business
When a customer asks AI for a recommendation, you do not get to choose which AI they used. They will use whatever is open on their phone or whatever their friend recommended. If your AI visibility report tells you "you appear in three out of four ChatGPT tests", that is useful, but it does not tell you what happened on Claude, or Gemini, or Grok, or inside paid Perplexity routing to Kimi.
A check has to cover the AI your customers are using. Not the AI someone listed in a launch announcement six months ago.
What the free discoverability check focuses on is the readiness signals AI models use to decide whether to recommend you in the first place - your website, your schema, your directory listings, your reviews, all the things AI cross-references when it picks a business. Get those gaps right first. A paid audit then tells you exactly how often you are being named across the live lineup as it stands today, and how often a competitor is being named instead.
Ask the question
If you are weighing up AI visibility tools, it is a fair question to ask any of them: how is the model lineup chosen, and how does it get refreshed when new models come out? Anyone running a good lineup will be happy to walk you through it. The answer tells you whether the tool you are paying for is keeping up with where AI is now, or whether it is still pointing at the AI landscape it was built against.
For our part, the live lineup is on our /models page. The snapshot today is eight platforms, twelve models. By the time you read this, that might already be different.
How findable is your business to AI?
Run a free check on your business name and town. Discoverability score, the specific gaps AI looks at, no account needed.
Check my AI discoverabilitySources
Live model lineup: /models
Our methodology: /methodology
Plans and what each includes: /pricing